
You are looking for information, articles, knowledge about the topic nail salons open on sunday near me 자료 구조 정리 pdf on Google, you do not find the information you need! Here are the best content compiled and compiled by the https://toplist.pilgrimjournalist.com team, along with other related topics such as: 자료 구조 정리 pdf 열혈 자료구조 pdf, 자료구조 책 pdf, c 언어 자료구조 pdf, 자료구조 종류, 열혈강 의 자료구조, 자료구조 기초, 자료구조 강의, 대표적인 자료구조
Table of Contents
자료구조 정리
- Article author: velog.io
- Reviews from users: 1170
 Ratings
Ratings - Top rated: 3.0
- Lowest rated: 1
- Summary of article content: Articles about 자료구조 정리 자료구조에서 효율적인 탐색 방법만을 고민할 것이 아니라, 효율적인 저장방법도 고민해야 한다. Binary Search Tree (이진 탐색 트리)는 이진 트리이며, … …
- Most searched keywords: Whether you are looking for 자료구조 정리 자료구조에서 효율적인 탐색 방법만을 고민할 것이 아니라, 효율적인 저장방법도 고민해야 한다. Binary Search Tree (이진 탐색 트리)는 이진 트리이며, … 2019-06-01 16:00 작성된 포스트
Naver Campus Hackday 2019 우수 참가자로 선정되어, 네이버 계열사인 (주)웍스모바일 에 기술면접을 보게 되었다(무려 1시간이나.. ㄷㄷ). 웍스모바일 면접 후기 등을 찾아보면서 공부해야겠지만 그 전에, 자료구조 등 기본적인 것들은 공부를 확실히 해야겠다는 생각이 들어, 여기다 정리하면서 공부…
- Table of Contents:
Array & LinkedList
Stack & Queue
Tree
HashTable
Graph

Algorithm – 자료구조 핵심정리
- Article author: devraphy.tistory.com
- Reviews from users: 3604 Ratings
- Top rated: 3.9
- Lowest rated: 1
- Summary of article content: Articles about Algorithm – 자료구조 핵심정리 자료구조 (Data Structure). a) 배열(Array). https://wikocs.net/22958. 한가지 데이터 타입의 데이터를 순차적으로 저장 및 정렬하는 자료구조 … …
- Most searched keywords: Whether you are looking for Algorithm – 자료구조 핵심정리 자료구조 (Data Structure). a) 배열(Array). https://wikocs.net/22958. 한가지 데이터 타입의 데이터를 순차적으로 저장 및 정렬하는 자료구조 … 1. 정의 a) 자료구조란? 대량의 데이터를 효율적으로 관리하기 위해, 데이터를 저장 및 정렬하는 방식을 말한다. 데이터를 어떤 방식으로 저장하고 정렬하느냐에 따라 추출 방식 등 데이터를 처리 및 조작하는데..
- Table of Contents:
1 정의
2 자료구조 (Data Structure)
태그
관련글
댓글1
공지사항
전체 방문자
티스토리툴바
[자료구조] 대표적인 자료구조 정리 — re-code-cord
- Article author: re-code-cord.tistory.com
- Reviews from users: 1329 Ratings
- Top rated: 3.5
- Lowest rated: 1
- Summary of article content: Articles about [자료구조] 대표적인 자료구조 정리 — re-code-cord [자료구조] 대표적인 자료구조 정리 · 배열 (Array) · 연결 리스트 (Linked List) · 스택 (Stack) · 큐 (Queue) · 해시 테이블 (Hash Table) · 그래프 (Graph). …
- Most searched keywords: Whether you are looking for [자료구조] 대표적인 자료구조 정리 — re-code-cord [자료구조] 대표적인 자료구조 정리 · 배열 (Array) · 연결 리스트 (Linked List) · 스택 (Stack) · 큐 (Queue) · 해시 테이블 (Hash Table) · 그래프 (Graph). 면접을 보면서 느꼈던 점은 자료구조와 알고리즘은 기본적인 것이라고 생각하는데, 막상 대답하고자 하면 명확하지 않았던 경우가 많았던 것 같다. 이번 기회에 확실히 공부해서 기초를 단단히 해서 보다 논리적..
- Table of Contents:
블로그 메뉴
인기 글
최근 댓글
최근 글
티스토리
티스토리툴바
![[자료구조] 대표적인 자료구조 정리 — re-code-cord](https://t1.daumcdn.net/tistory_admin/static/images/openGraph/opengraph.png)
자료구조 정리 :: 👨💻☕
- Article author: pyoungt.tistory.com
- Reviews from users: 13310 Ratings
- Top rated: 3.7
- Lowest rated: 1
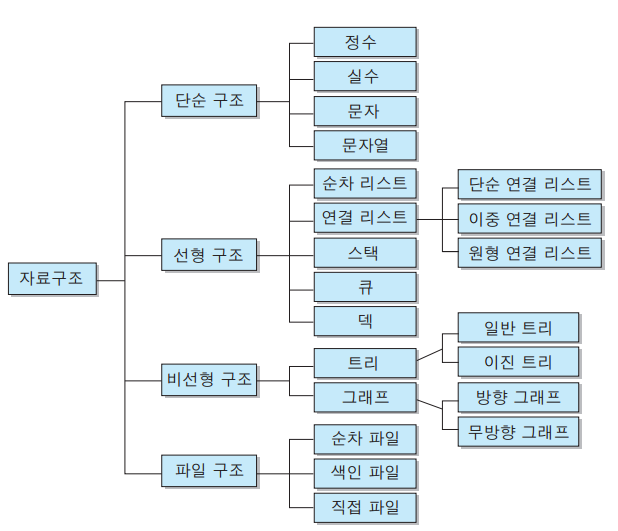
- Summary of article content: Articles about 자료구조 정리 :: 👨💻☕ 기본 자료구조 종류. 선형 자료구조 (linaer). – 배열 (Array). – 연결리스트 (Linked List). – 스택 (Stack). – 큐 (Queue). 비선형 자료구조 … …
- Most searched keywords: Whether you are looking for 자료구조 정리 :: 👨💻☕ 기본 자료구조 종류. 선형 자료구조 (linaer). – 배열 (Array). – 연결리스트 (Linked List). – 스택 (Stack). – 큐 (Queue). 비선형 자료구조 … 기본 자료구조 종류 선형 자료구조 (linaer) – 배열 (Array) – 연결리스트 (Linked List) – 스택 (Stack) – 큐 (Queue) 비선형 자료구조 (non-linear) – 트리 (Tree) – 그래프 (Graph) 1. 배열 1) 정의 같은 자..
- Table of Contents:
자료 구조(Data Structure) 개념 및 종류 정리
- Article author: bnzn2426.tistory.com
- Reviews from users: 38778 Ratings
- Top rated: 4.7
- Lowest rated: 1
- Summary of article content: Articles about 자료 구조(Data Structure) 개념 및 종류 정리 자료 구조란? 데이터 값의 모임, 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 구분 … …
- Most searched keywords: Whether you are looking for 자료 구조(Data Structure) 개념 및 종류 정리 자료 구조란? 데이터 값의 모임, 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 구분 … 자료 구조란? 데이터 값의 모임, 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 구분하여 표현한 것. 예를 들어 한정된 크기의 책장이 있고, 넣어..
- Table of Contents:
티스토리 뷰
자료 구조란
자료 구조와 알고리즘의 관계
필수 자료 구조 8개
References
티스토리툴바
열혈 자료구조 정리(完) :: 1D1C
- Article author: 1d1cblog.tistory.com
- Reviews from users: 41972 Ratings
- Top rated: 4.4
- Lowest rated: 1
- Summary of article content: Articles about 열혈 자료구조 정리(完) :: 1D1C 회사 스터디 정리 및 공부용으로 정리하려고 합니다. … 오렌지 미디어에서 볼 수 있는 열혈 자료구조의 강의 영상은 책을 구매하시고 책 뒷편에 … …
- Most searched keywords: Whether you are looking for 열혈 자료구조 정리(完) :: 1D1C 회사 스터디 정리 및 공부용으로 정리하려고 합니다. … 오렌지 미디어에서 볼 수 있는 열혈 자료구조의 강의 영상은 책을 구매하시고 책 뒷편에 … 회사 스터디 정리 및 공부용으로 정리하려고 합니다. 책은 오렌지 미디어의 윤성우의 열혈 자료구조와 오렌지 미디어 강좌를 보고 공부 및 정리한 포스팅입니다. ====== 오렌지 미디어 ====== www.orentec.co.kr..개인공부 정리 블로그
- Table of Contents:
열혈 자료구조 정리(完)
티스토리툴바

개념 정리 – (4) 자료 구조 편
- Article author: brunch.co.kr
- Reviews from users: 44045 Ratings
- Top rated: 3.2
- Lowest rated: 1
- Summary of article content: Articles about 개념 정리 – (4) 자료 구조 편 모든 경우에 적합한 자료 구조는 없다. 예를 들어 배열은 순차 탐색이 빠르게 가능하지만 중간 삽입, 삭제가 매우 느리다. 연결 리스트는 중간 삽입, 삭제 … …
- Most searched keywords: Whether you are looking for 개념 정리 – (4) 자료 구조 편 모든 경우에 적합한 자료 구조는 없다. 예를 들어 배열은 순차 탐색이 빠르게 가능하지만 중간 삽입, 삭제가 매우 느리다. 연결 리스트는 중간 삽입, 삭제 … 우리가 배운 개념이 어디서 어떻게 쓰이는지 알아보자 | 드디어 본격적으로 코딩의 영역에 들어서게 됐다. 일상적으로 쓰고 있던 배열부터 시작하여 얼핏 봐서는 잘 이해가 되지 않는 복잡한 자료 구조까지, 자료 구조의 세계는 방대하다. 학부 수준 자료 구조 강의에서는 보통 힙이나 해싱까지 다루는 것 같다. 트리와 같은 자료 구조들은 배우면서도 왜 배우는지 잘 이해하지 못하는 경우가 많은데, 실제 예를 들어가면서 필요
- Table of Contents:

[IT 개념 정리] 자료구조
- Article author: han-1ife.tistory.com
- Reviews from users: 9335 Ratings
- Top rated: 3.7
- Lowest rated: 1
- Summary of article content: Articles about [IT 개념 정리] 자료구조 [IT 개념 정리] 자료구조. Han_92 2020. 2. 23. 19:53. 1. 자료구조란? 사전적인 의미 – 자료의 집합으로 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 … …
- Most searched keywords: Whether you are looking for [IT 개념 정리] 자료구조 [IT 개념 정리] 자료구조. Han_92 2020. 2. 23. 19:53. 1. 자료구조란? 사전적인 의미 – 자료의 집합으로 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 … 1. 자료구조란? 사전적인 의미 – 자료의 집합으로 각 원소들이 논리적으로 정의된 규칙에 의해 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 구분하여 표현한 것. 목적 – 자료를 저장, 관리..
- Table of Contents:
태그
‘Learn이론 정리’ Related Articles
티스토리툴바
![[IT 개념 정리] 자료구조](https://img1.daumcdn.net/thumb/R800x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FwSvbv%2FbtqCcVIC8kz%2F5YZB7atCHgx3QPyyAQLyK0%2Fimg.png)
See more articles in the same category here: Toplist.pilgrimjournalist.com/blog.
자료구조 정리
2019-06-01 16:00 작성된 포스트
Naver Campus Hackday 2019 우수 참가자로 선정되어, 네이버 계열사인 (주)웍스모바일 에 기술면접을 보게 되었다(무려 1시간이나.. ㄷㄷ). 웍스모바일 면접 후기 등을 찾아보면서 공부해야겠지만 그 전에, 자료구조 등 기본적인 것들은 공부를 확실히 해야겠다는 생각이 들어, 여기다 정리하면서 공부하기로 했다.
Array & LinkedList
우선 자료구조의 기본이라고 할 수 있는 Array 에 대해서 보자. Array는 논리적 순서와 물리적 순서가 일치한다. 따라서 index값을 통한 원소 접근이 용이하며, 구현이 쉽다. 단점으로는 삽입, 삭제 등에 대한 연산에 필요한 Cost가 높다는 것이다. 삭제의 경우 순서를 맞추기 위해, 뒤의 원소들을 모두 앞으로 Shift연산을 해줘야 하며, 삽입의 경우도 삽입한 인덱스 포함, 그 뒤의 인덱스들에 Shift 연산을 해줘야 한다.
배열의 삽입/삭제 연산에 대한 비효율성을 극복하고자 등장한 것이 LinkedList 이다. Array와 LinkedList의 차이점은, Array는 논리적, 물리적 저장이 순서대로 되어있으나, LinkedList는 논리적으론 순서대로 되어있으나 물리적으론 순서대로 되어있지 않다. 대신 LinkedList는 각 원소가 다음 index 위치에 해당하는 물리적 주소를 가지고 있다. 그렇기에 삽입/삭제시에는 데이터를 Shift할 필요 없이, 해당되는 원소의 물리적 주소만 변경해주면 된다. 하지만 이 같은 특징 때문에 원하는 index를 참조하려면, 1번 index부터 차례대로 접근해야 한다는 비효율성이 있다.
Stack & Queue
Stack 은 선형 자료구조의 일종으로, FILO(First In Last Out)의 대표적인 예시로 들 수 있으며, 말 그대로 먼저 들어갔다가 나중에 나오는 구조이다. 즉 가장 나중에 들어간 원소가 가장 먼저 나오게 된다. 미로찾기, 괄호 유효성 체크 등에 활용된다.
Queue 역시 선형 자료구조이며, Stack과는 반대로 FIFO(First In First Out) 구조이다. 줄을 선다는 뜻과 같게, 먼저 들어간 원소가 가장 먼저 나온다. 작업 우선순위, Heap 구현 등에 사용된다.
Tree
Tree 는 Stack, Queue와는 다르게 비선형 자료구조로, 계층적 구조를 표현하는 자료구조이다. 실제 데이터를 삽입하고 삭제한다는 생각 이전에, 표현에 집중하자. 트리의 구성 요소는 다음과 같다.
Node (노드) : 트리를 구성하고 있는 원소 그 자체를 말한다.
Edge (간선) : 노드와 노드사이를 연결하고 있는 선을 말한다.
Root(Node) : 트리에서 최상위 노드를 말한다.
Terminal(Node) : 트리에서 최하위 노드를 말한다. Leaf Node라고도 한다.
Internal(Node) : 트리에서 최하위 노드를 제외한 모든 노드를 말한다.
(이미지 출처 : http://blog.daum.net/_blog/BlogTypeView.do?blogid=0JHcJ&articleno=8382646&categoryId=791705®dt=20100728174800)
Binary Tree (이진트리)
Binary Tree는 Root 노드를 포함, Leaf 노드를 제외한 모든 노드의 자식이 두 개인 것을 말한다. 공집합 역시 노드로 인정한다. 노드로 이루어진 각 층을 Level 이라 하며, Level의 수를 이 트리의 height 라 한다.
이진트리에는 모든 Level이 가득 찬 이진 트리인 Full Binary Tree(포화 이진 트리) 와 위에서 아래로, 왼쪽에서 오른쪽으로 순서대로 채워진 트리인 Complete Binary Tree(완전 이진 트리) 가 있다(두 트리의 차이점을 알아두면 좋을 것 같다). 배열로 포화 이진트리와 완전 이진트리를 구현했을 때, 노드의 개수 n에 대해서 i번째 노드에 대해서 parent(i) = i/2 , left_child = 2i, right_child = 2i + 1 의 인덱스 값을 갖는다.
BST, Binary Search Tree (이진 탐색 트리)
자료구조에서 효율적인 탐색 방법만을 고민할 것이 아니라, 효율적인 저장방법도 고민해야 한다. Binary Search Tree (이진 탐색 트리)는 이진 트리이며, 데이터를 저장하는 특별한 규칙이 있다. 그 규칙으로 찾고자 하는 데이터를 찾을 수 있다.
이진 탐색 노드에 저장된 값은 유일한 값이다. 루트 노드의 값은 왼쪽에 있는 모든 노드의 값보다 크다. 루트 노드의 값은 오른쪽에 있는 모든 노드의 값보다 작다. 각 서브 트리별로 2, 3번 규칙을 만족한다.
저장할 때 위의 규칙대로 잘 저장하기만 하면, 루트 노드로부터 원하는 값을 찾아나가는 것은 어렵지 않을 것이다. 하지만 값이 추가되고 삭제됨에 따라, 한 쪽에만 치우친 Skewed Tree(편향 트리)가 될 가능성이 있다. 이를 해결하기 위해 Rebalancing 이라는 기법을 사용하여 트리를 재조정하게 된다.
(이미지 출처 : https://songeunjung92.tistory.com/31)
평균 탐색시간은 O(logN), 최악 탐색시간은 O(N)
Red Black Tree
RBT(Red-Black Tree)는 위에서 설명한 Rebalancing 기법의 하나로, 기존 이진탐색트리의 삽입, 삭제, 탐색의 비효율성을 개선한 방법이다. RBT는 다음과 같은 규칙을 따른다.
각 노드는 Red 혹은 Black 이라는 색깔을 갖는다. 루트 노드는 Black 이다. 각 말단 노드(NIL)는 Black 이다. 어떤 노드의 색이 Red 라면, 두 자식 노드의 색은 모두 Black 이다. 어느 한 노드로부터 리프노드(NIL)까지의 Black 의 수는 리프노드를 제외하면 모두 같다(이를 Black-Height 라 한다).
RBT 특징으로는 다음과 같다.
Binary Search Tree이므로, BST의 특징을 모두 갖고있다. 루트로부터 말단 노드까지의 최소 경로는 최대 경로의 두 배보다 크지 않다. 이를 Balanced 한 상태라 한다. 노드의 Child가 없을 경우, Child를 가리키는 포인터에 NIL(혹은 NULL)값을 저장한다. 이러한 NIL 노드들을 말단 노드로 간주한다. 말단 노드이기 때문에, 이 노드들의 색은 Black 이다.
RBT에서의 삽입 과정은 다음과 같다. 우선 새로 삽입한 노드를 BST 특성을 유지하며 삽입한 후, 색을 Red 로 칠한다. 이는 Black-Height 의 수를 최대한 유지하기 위해서이다. 삽입 결과 RBT 특성이 위배된다면, 노드의 색을 다시 칠한다. 만일 Black-Height 특성, 즉 위의 5번 규칙이 위배되었다면, Rotation 을 통해 조정한다.
삭제 과정 역시 마찬가지로 우선 BST 특성을 유지하며 노드를 삭제한다. 삭제될 노드의 Child와 색깔로 Rotation 방법이 정해진다(후에 삭제 과정을 자세히 조사하겠다).
Binary Heap
Binary Heap은 배열에 기반한 완전 이진탐색트리이며, Max-Heap과 Min-Heap이 있다. Max-Heap은 상위 노드의 값이 하위 각 노드의 값보다 크며, Min-Heap은 반대로 상위 노드의 값이 하위 각 노드의 값보다 작다(형제 노드끼리는 상관없다). 이 성질을 이용하면 최대, 최솟값을 찾아내는 것이 훨씬 용이하다.
(이미지 출처 : https://ieatt.tistory.com/40)
HashTable
HashTable은 내부적으로 배열을 사용하며, 평균적으로 빠른 탐색속도(O(1))를 갖는다. 평균적으로라는 의미는 충돌을 고려하지 않았을 때이다. Key값을 해시함수를 통하여 인덱스로 변환 후에, 그 인덱스에 집어 넣는다. 만약 다른 Key값을 해시함수를 통과시켰는데 같은 인덱스가 나온다면, 그걸 충돌이라고 한다.
충돌 해소법(Resolve Conflict) 방법에는 기본적인 두 가지 방법이 있다.
Open Address 방식 (개방 주소법)
충돌 발생 시, 다른 인덱스를 찾는다.
Linear Probing : 순차적으로 탐색하여 다음 인덱스를 찾는다.
Quadratic Probing : 2차 함수를 이용해 탐색할 위치를 찾는다.
Double Hashing Probing : 충돌 발생시 새로운 해시함수를 활용하여 주소를 찾는다. Separate Chaining 방식 (분리 연결법)
충돌 발생 시 다른 인덱스를 찾는 대신, 그 인덱스에다가 연결하는 방법.
연결 리스트를 이용하여 연결하는 방법과, Tree(RBT)를 이용하여 연결하는 방법이 있다. 두 방식 모두 Worst Case가 O(M)이다. 데이터의 크기가 크다면 Separate Chaining, 아니라면 Open Address 방식이 더 낫다.
Hashmap의 Resize : 일정 개수이상 크기가 커지면, 해시 버킷의 크기를 두 배로 늘림.
Graph
정점과 간선의 집합이며, 일종의 Tree이다.
Undirected와 Directed Graph가 있는데, 방향성 유무로 결정된다.
Degree란 Undirectd Graph에서 정점에 연결된 간선의 개수이다. Directed Graph에서의 Degree는 방향성이 있기 때문에 둘로 나뉘는데, 나가는 간선의 개수는 Outdegree, 들어오는 간선의 개수를 Indegree라 한다.
가중치 그래프 란 간선에 가중치를 둔 그래프, 부분 그래프 란 한 그래프의 일부 정점 및 간선으로 이루어진 그래프.
그래프의 구현 방법 :
인접 행렬 : 정방 행렬을 사용하여 구현. 연결 관계를 O(1)로 파악 가능. 공간 복잡도는 O(2V) 인접 리스트 : 리스트를 사용하여 구현. 정점간 연결 여부 파악애 오래 걸림. 공간 복잡도는 O(E + V)
탐색 방법에는 깊이 우선 탐색(DFS, Depth First Search)와 너비 우선 탐색(BFS, Breadth First Search)이 있다.
깊이 우선 탐색은 말 그대로 깊숙히 들어가서 탐색하고 나오는 것이며, 유용한 자료구조는 Stack이다.
너비 우선 탐색은 임의의 한 정점에 대해 인접한 정점을 queue에 넣고(enqueue), dequeue연산에서 나온 하나의 정점으로 들어가서 그 정점의 인접한 정점을 다시 Queue에 넣어서 탐색하는 방식. BFS로 찾은 경로는 최단 경로이다.
자료구조 정리
Algorithm – 자료구조 핵심정리
데이터를 어떤 방식으로 저장하고 정렬하느냐에 따라 추출 방식 등 데이터를 처리 및 조작하는데 필요한 코드가 달라진다.
대량의 데이터를 효율적으로 관리하기 위해, 데이터를 저장 및 정렬하는 방식 을 말한다.
https://wikidocs.net/22958
각 데이터마다 index를 부여 하여 데이터 검색에 용이(장점)
한가지 데이터 타입 의 데이터를 순차적 으로 저장 및 정렬하는 자료구조
https://galid1.tistory.com/483
저장될 수 있는 데이터의 최대개수를 미리 정해야한다. 즉, 저장공간의 낭비가 발생 한다. (단점)
이름처럼 데이터를 쌓는 방식(LIFO) 으로 데이터를 저장 및 정렬하는 자료구조
https://beginnersbook.com/2013/12/linkedlist-in-java-with-example/
데이터가 삭제하면 삭제된 데이터의 이전과 다음 데이터의 연결을 재구성 해야한다. (단점)
포인터를 이용해 연결노드를 찾는 시간이 필요하다. (접근속도가 느리다)
노드(Node): 데이터의 저장단위로, 데이터 값과 포인터(주소값)를 한 쌍 으로 구성한다.
크기의 가변성을 구현하기 위해 노드와 포인터를 사용하여 데이터를 저장 및 연결한다.
배열(Array)의 단점이 보완된 형태의 자료구조로, 크기가 가변적인 배열(장점)
연결 리스트와는 다르게, 한 방향이 아니라 앞뒤 양방향으로 검색이 가능 하다. (장점)
이중연결리스트는 이전과 다음 데이터의 주소값을 갖고 있는 연결리스트 다.
Key와 Value를 한 쌍으로 저장하는 자료구조
Key를 Hash함수로 연산하여 나온 결과 값(해시값, 해시주소)으로 Value를 찾는 방식을 사용한다.
Key를 이용하여 Value를 빠르게 검색할 수 있다.(장점)
특정 데이터의 중복을 쉽게 확인할 수 있다.(장점)
저장공간을 많이 필요로 한다(단점). 그러므로 해시테이블은 공간과 탐색시간을 맞바꾼 기법이라고 표현한다.
– 해시테이블의 빠른 검색능력의 이점으로 인해, 해시값의 중복확률을 줄이기 위해 해시테이블의 저장공간을 크게 잡아서 사용한다는 의미다.
[자료구조] 대표적인 자료구조 정리
면접을 보면서 느꼈던 점은 자료구조와 알고리즘은 기본적인 것이라고 생각하는데, 막상 대답하고자 하면 명확하지 않았던 경우가 많았던 것 같다. 이번 기회에 확실히 공부해서 기초를 단단히 해서 보다 논리적으로 문제를 해결하고 싶다. 저번 글 에서 자료구조에 대한 전반적인 내용을 다뤘다면, 이번에는 대표적인 자료구조들을 살펴보고 각각의 장단점과 특징을 비교해보자.
배열 (Array)
배열은 가장 기본적인 데이터 구조다. 배열은 인덱스(Index)와 인덱스에 해당하는 요소(Element)로 구성된다.
특징
길이가 고정되어 생성된다. (정적 메모리 할당) Random Access를 지원한다. 즉, 인덱스를 통해서 각 요소에 직접 접근할 수 있는 특징이 있다. 배열은 논리적 순서와 물리적 순서가 일치한다. 인접한 메모리 위치에 연이어 저장된다.
시간 복잡도
검색 (Search) : 요소마다 인덱스를 부여했기 때문에, 특정 요소를 접근하는 시간 복잡도는 O(1)이다. 하지만, 인덱스를 모르는 특정 값을 찾기 위해서는 배열의 모든 요소들을 살펴봐야 하기 때문에 O(n)의 시간 복잡도를 갖는다. 추가/삭제 (Insert/Delete) : 삽입이나 삭제를 하기 위해서는 길이가 고정되어 있기 때문에 차례대로 한 칸씩 밀어야 하는 과정이 필요하고 그 과정에서 O(n)의 시간 복잡도가 생긴다.
연결 리스트 (Linked List)
배열의 추가/삭제 연산에 대한 비효율성을 극복하고자 등장한 데이터 구조이다. 각 요소는 다음 노드 연결에 대한 정보를 담은 포인터 또는 주소와 함께 노드에 저장된다. 단일 연결 리스트, 이중 연결 리스트, 원형 연결 리스트 등의 종류가 있다.
특징
새로운 요소가 추가될 때 런타임에 메모리를 할당한다. (동적 메모리 할당) Sequential Access를 지원한다. 요소에 접근할 때 순차적으로 접근해야 하는 특징이 있다. 인덱스나 위치와 같은 물리적 배치를 사용하지 않고 참조 시스템(다음 노드 연결에 대한 포인터 또는 주소)을 사용한다.
시간 복잡도
검색 (Search) : 처음부터 순차적으로 접근해야 하기 때문에 O(n)의 시간 복잡도를 갖는다. 추가/삭제 (Insert/Delete) : 동적인 메모리 크기를 갖기 때문에, 새로운 요소를 추가하거나 삭제할 경우에 해당되는 부분만 변경하면 되기 때문에 O(1)의 시간 복잡도를 갖는다.
Array와 Linked List의 차이는 무엇일까?
데이터의 접근의 경우 Array는 Random Access를 그리고 Linked List는 Sequential Access를 지원한다. 따라서, 특정 요소에 접근하는 경우 Array는 직접 접근할 수 있어 효율적이고, Linked List는 처음부터 순차적으로 접근해야 해서 비효율적이다.
반면에 데이터의 추가/삭제 Array의 경우 크기가 고정되어 있어서, 추가 및 삭제를 위해서는 다른 요소들의 주소도 전부 변경해야 하기 때문에 비효율적인데, Linked List의 경우 추가 및 삭제 시 해당되는 요소의 메모리 주소만 변경하면 되기 때문에 보다 효율적이다.
그리고 메모리 할당에서도 차이가 나는데 Array는 선언 시 요소들을 인접한 메모리 위치에 연이어 저장하고 크기가 고정되어 있는 정적 메모리 할당, Linked List의 경우 새로운 요소가 추가되면 메모리를 할당하고 그 정보를 저장하는 동적 메모리 할당.
스택 (Stack)
순서가 보존되는 선형 자료구조의 일종으로, LIFO(Last In First Out) 메커니즘을 갖고 있다.
특징
데이터를 받는 순서대로 정렬한다. LIFO, 마지막으로 입력된 것을 순차적으로 가져오는 방법을 갖고 있는 것이 특징이다. (FILO도 동일한 의미다) 동적 메모리
시간 복잡도
검색 (Search) : 처음부터 순차적으로 접근해야 하기 때문에 O(n)의 시간 복잡도를 갖는다. 추가/삭제 (Insert/Delete) : 가장 위에 데이터를 추가하거나 삭제하기 때문에 O(1)의 시간 복잡도를 갖는다.
큐 (Queue)
순서가 보존되는 선형 자료구조의 일종으로, FIFO(First In First Out) 메커니즘을 갖고 있다.
특징
데이터를 받는 순서대로 정렬한다. FIFO, 가장 먼저 입력된 것을 순차적으로 가져오는 방법을 갖고 있는 것이 특징이다. 동적 메모리
시간 복잡도
검색 (Search) : 처음부터 순차적으로 접근해야 하기 때문에 O(n)의 시간 복잡도를 갖는다. 추가/삭제 (Insert/Delete) : 가장 위에 데이터를 추가하거나 삭제하기 때문에 O(1)의 시간 복잡도를 갖는다.
Stack과 Queue의 차이는 무엇일까?
두 자료구조 모두 순서가 보존되는 선형 자료구조의 일종이며, 동시에 Push와 Pop과 같은 핵심적인 기능만 알면 되는 추상적 자료구조이기도 하다. 가장 큰 차이점은 처리하는 순서에 있는데, Stack은 가징 마지막으로 입력된 것부터 Queue는 가장 먼저 입력된 것부터 처리하는 메커니즘을 갖는다. 이러한 특징으로 Stack은 DFS나 재귀에 자주 사용되고, Queue는 BFS나 캐시를 구현할 때 사용된다.
해시 테이블 (Hash Table)
해시 테이블은 키(Key)와 값(Value)로 데이터를 저장하는 자료구조 중 하나로 빠른 검색이 필요할 때 용이하다. 해시 테이블을 구현하기 위해서는 연결 리스트와 해시 함수(Hash Function)가 필요하다. 해싱(Hashing)은 해시 함수를 통해서 임의의 값을 고정된 크기의 값으로 변환하는 작업을 말하는데, 키 값을 입력받아서 해시 함수를 통해 얻은 해시(Hash)를 배열의 인덱스로 환산해서 값에 접근하는 것을 의미한다.
특징
키 값을 배열의 인덱스로 사용하기 때문에, 값을 직접 접근할 수 있다. 따라서, 해시 테이블의 평균 시간 복잡도는 O(1)이다.(운이 없어, 충돌(Collision)이 일어나는 경우 O(n)) 충돌이 발생할 수 있다. 이 경우 분리 연결법(Separate Chainging) 혹은 개방 주소법(Open Address)을 사용하여 해결한다. 데이터가 저장되기 이전에 미리 공간을 만들어야한다. 공간 복잡도가 크다. 해시 함수를 통해서 배열 인덱스의 범위를 조절할 수 있다. 이를 리사이징(Resizing)이라고 한다. 키와 해시의 연관성이 없어 보안에도 자주 사용된다.
충돌 해결방법은 무엇이 있을까?
(1) Separate Chaning : Linked List 혹은 Tree를 사용하는 방법이다. 충돌이 발생하는 경우 인덱스가 가리키고 있는 값에 노드를 추가하여 값을 추가한다. 대신, 두 방법 모두 많이 추가하면 비효율적이다.
(2) Open Address : 해시 테이블의 빈공간을 사용하는 방법이다. 추가적인 메모리 공간을 필요하지 않은 장점이 있다. 그 방법에는 Linear Probing, Quandratic Probing, Double Hasing 등이 있다.
그래프 (Graph)
그래프는 비선형 자료구조로, 노드(Node)/정점(Vertice)과 이들 사이를 연결하는 엣지(Edge)로 구성된 자료구조를 의미한다.
특징
그래프는 방향이 있을 수도(Directed) 없을 수도(Undirected) 있다. 다양한 구조로 설계된다. 구조에 따라서 시간 복잡도가 달라지고 다양하게 응용이 가능하다. 새로운 요소들의 추가/삭제가 용이하고 효율적이다. 시간 복잡도/공간 복잡도를 이야기할때 노드(N)/정점(V)과 엣지(E)의 수를 사용하여 표현한다.
시간 복잡도
두 노드의 연결 확인 : 인접 행렬의 경우 고유 인덱스로 바로 접근 가능하여 O(1)의 시간 복잡도를 갖는다. 인접 리스트의 경우 한 노드의 인접 리스트 안의 특정 노드가 있는지 확인해야 하기 때문에, 최악의 경우 전체를 봐야하므로 O(N)/O(V)의 시간 복잡도를 갖는다. 한 노드에 연결된 모든 노드 확인 : 인접 행렬의 경우 특정 노드를 나타내는 행렬을 돌아서 연결된 노드를 가져와야 하기 때문에, O(N)/O(V) 의 시간 복잡도를 갖는다. 인접 리스트의 경우 연결된 노드의 갯수는 곧 엣지의 갯수이므로, 엣지의 갯수만 확인하면 되므로 O(E)의 시간 복잡도를 갖는다. 추가/삭제 (Insert/Delete) : 추가의 경우 노드/정점이나 엣지 모두 O(1)의 시간 복잡도를 갖는다. 하지만, 삭제의 경우에는 노드/정점의 경우 특정 노드/정점을 찾는 시간과 그와 연결된 엣지를 삭제해야 하므로 O(N+E)/ O(V+E)의 시간 복잡도를 갖는다. 엣지의 경우 특정 엣지를 찾는 시간이 소요되므로 O(E)의 시간 복잡드를 갖는다.
트리 (Tree)
트리는 비선형 자료구조로, 노드로 구성된 계층적 자료구조이다. 최상위 노드(Root)를 만들고, 부모(Parent) 노드에 자식(Child) 노드를 추가하고 그리고 그 자식 노드가 부모 노드로써 또 다른 자식 노드를 추가하는 구조를 가지고 있다.
특징
트리에 또 다른 트리가 있는 재귀적 자료구조이다. 데이터를 순차적으로 저장하지 않는, 비선형 자료구조이다. 이진트리(Binary Tree), 이진탐색트리(BST, Binary Search Tree), 균형트리(B-Tree, Balanced Tree), 힙트리(Heap Tree) 등 다양한 종류가 존재한다.
Reference
So you have finished reading the 자료 구조 정리 pdf topic article, if you find this article useful, please share it. Thank you very much. See more: 열혈 자료구조 pdf, 자료구조 책 pdf, c 언어 자료구조 pdf, 자료구조 종류, 열혈강 의 자료구조, 자료구조 기초, 자료구조 강의, 대표적인 자료구조